A Developer's Guide to Generate Mock Data
If you're a developer, you know the drill. You need realistic, structured data to build out your APIs and frontends, but the backend isn't ready yet. This is where generating good mock data becomes a game-changer. It's the key to testing your applications thoroughly, letting your frontend and backend teams work at the same time, and even demoing features before they're fully wired up.
Why Better Mock Data Builds Better Software

Before we jump into the "how," let's talk about the "why." Getting mock data right is a non-negotiable skill in modern development. We're not just talking about dropping in "lorem ipsum" and calling it a day; we're talking about building resilient, predictable apps that don't fall over when they encounter real, messy data.
I've seen it happen countless times. A team simulates user data with simple placeholders like "John Doe." Then, the app goes live, and real data floods in—names with special characters, unexpectedly long addresses, or null values where you didn't expect them. Suddenly, the UI shatters. It’s a classic, frustrating problem, and it’s completely avoidable.
Speed Up Your Workflow and Ship Higher Quality Code
When you get your mock data right, it tears down the walls between teams. By generating data that perfectly matches the final API contract, you unlock true parallel development. Your frontend devs are no longer blocked, waiting for a live endpoint to hit.
This simple shift in workflow brings some serious wins:
- Faster Turnaround: Teams can build and test their respective parts at the same time, which dramatically shortens the whole development cycle.
- More Reliable Tests: Your automated tests become far more powerful when they run against varied, realistic data. This is how you catch those tricky edge cases before they ever see the light of day.
- Fewer Production Fires: You can simulate all sorts of scenarios—empty arrays, missing fields, weirdly long strings—to make sure your app is truly robust.
This isn't just a niche trick; it's a growing industry standard. The synthetic data generation market was valued at USD 576 million and is on track to blow past USD 3.4 billion by 2030. That’s a clear signal that the old ways of using limited, real-world datasets are on their way out. You can discover more about this trend and its impact on software development.
Your First Mock API in Under 5 Minutes
Let's cut right to the chase. Forget about wrestling with complex config files or spinning up servers just to get some dummy data. We're going to go from zero to a live, functional mock API endpoint in less time than it takes to make a cup of coffee. The whole point is to get you unblocked and working now.
Picture this: you're building a new user dashboard and need a list of users to populate it. The backend isn't ready. No problem. With a tool like dotMock, you can generate a realistic endpoint right from your terminal, often with a single command.
The Magic of Zero-Config
Modern mocking tools are smart. They can figure out what you probably need without you having to spell it all out. You don't have to sit there defining every single data field if you just need a standard structure to get started.
For instance, if you tell dotMock you need a /users endpoint, it's intelligent enough to generate a JSON array of user objects. It'll automatically whip up standard fields like an ID, a name, and an email. This is a huge leg up when you're just trying to get the UI roughed in.
My Advice: Always start with the simplest version of your data. Don't get bogged down in perfecting the schema right away. The goal is to get a working endpoint up and running to unblock your development. You can layer on the complexity later.
Here’s a look at what that basic, auto-generated response might look like.
See? Without any specific instructions, the tool created logical fields like id, name, and email and filled them with believable placeholder data.
This kind of immediate feedback is what makes modern development so fast. You've got a live URL your frontend can hit right away. Once you have your mock API running and want to dive deeper into connecting it properly, checking out a practical API integration tutorial is a great next step. This instant endpoint is the foundation for everything else you'll build.
Crafting Custom Data That Mirrors Reality
So, you've got the basics down. But generic data only gets you so far. To build applications that can handle the real world, you need data that's just as messy and complex. This is where we move beyond simple user lists and start generating mock data that trulystress-tests your app and uncovers those tricky edge cases.
Let's think about a common scenario: an e-commerce platform. A simple list of user names won't do the trick. You need to mimic a real product API response, complete with nested customer reviews, inventory levels that change, and even randomized prices. This is how you find out what happens when a five-star review has a super long comment or a product suddenly sells out.
Taking the time to create this level of detail pays off big time, boosting everything from developer speed to the quality of your testing.
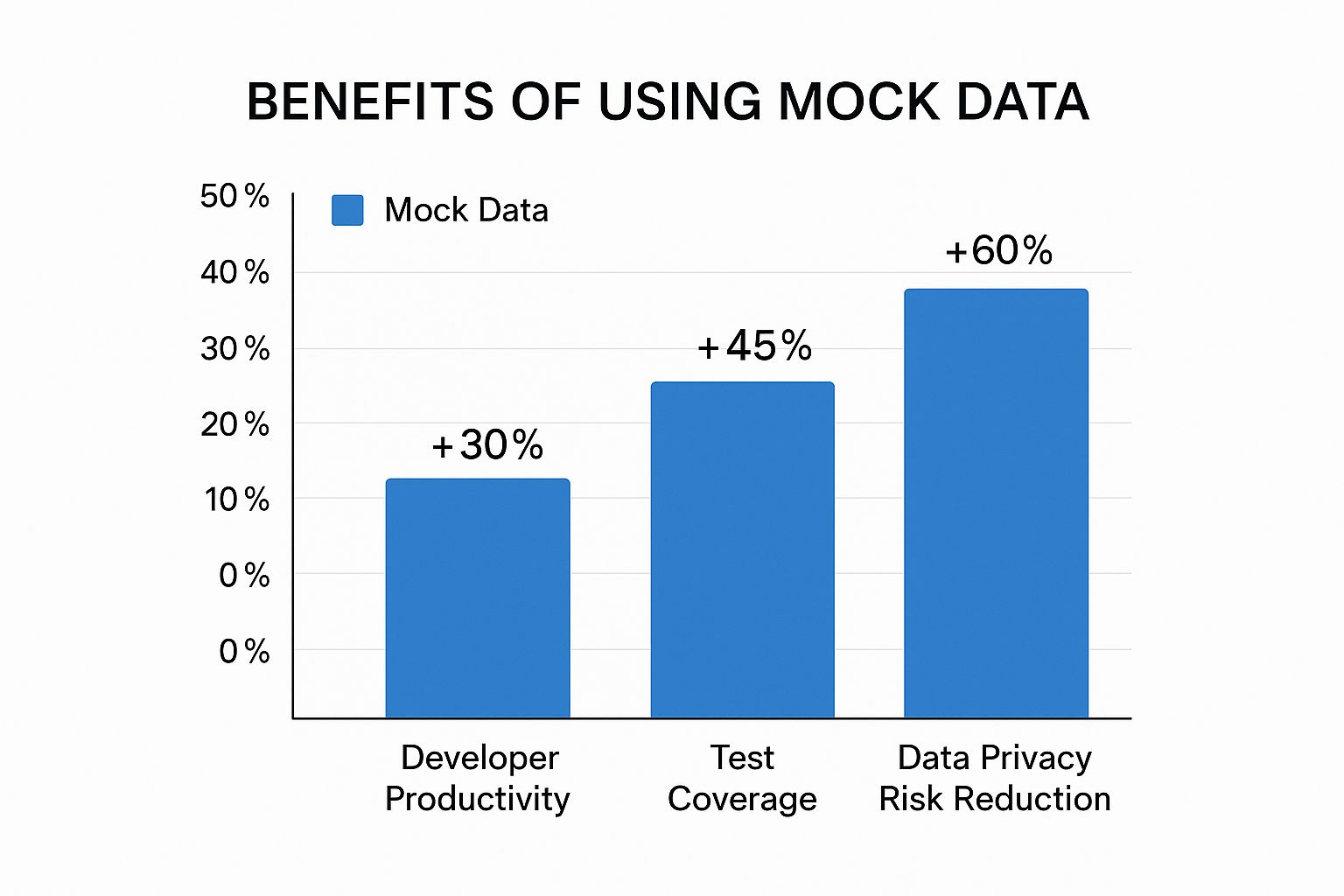
As you can see, one of the biggest wins is a 60% reduction in data privacy risk. That’s huge, especially when using real customer data is a complete non-starter.
Defining Complex and Nested Data Structures
The secret to creating this realism is using dynamic values. Instead of just hardcoding "123 Main St," you can generate thousands of believable street addresses, product names, or even valid-looking credit card numbers to test your validation logic.
This is where a library like Faker.js comes in handy. It gives you a massive library of data types to pull from. To get a feel for how it works within the platform, you can dive into the dotMock documentation on Faker syntax.
This dynamic approach isn't just for web apps. Think about AI and autonomous driving, where high-quality synthetic data is absolutely critical for training models. With a projected 4.5 million autonomous vehicles hitting U.S. roads by 2035 and 34% of companies already using AI, the demand for sophisticated, realistic data is only going to grow.
Key Takeaway: Realistic mock data isn't just about populating a UI. It's about simulating the chaos of the real world. By defining nested objects and dynamic values, you're building a safety net that catches bugs before they ever make it to production.
To make this a bit more tangible, here are some of the most useful generators I find myself coming back to again and again.
Essential Generators for Believable Mock Data
This table is a quick reference for some of the most useful built-in data generators to make your mock data more believable and varied.
| Generator Type | Example Output | Common Use Case |
|---|---|---|
name.fullName |
"Jane Doe" | Populating user profiles or contact lists. |
location.streetAddress |
"123 Main St" | Filling out shipping or billing address forms. |
image.url |
"https://loremflickr.com/640/480" | Displaying placeholder images for products or avatars. |
lorem.paragraph |
"Lorem ipsum dolor sit amet..." | Generating block text for blog posts or product descriptions. |
number.int |
87 |
Simulating IDs, quantities, or inventory counts. |
date.past |
"2023-10-26T14:30:00.000Z" | Creating timestamps for user signups, orders, or comments. |
Using a mix of these generators is how you start building truly dynamic and useful mock APIs. For that e-commerce example, a product endpoint might include:
- A
reviewsarray filled with nested objects, each with its own author, rating, and text. - An
inventoryfield with a random integer to simulate stock levels. - A
pricethat varies to test different currency formatting.
Simulating API Errors and Network Latency

It’s one thing to test the "happy path," but let's be honest—real-world applications rarely stay on that path for long. APIs go down, networks get sluggish, and servers just stop responding. If you want to build a truly resilient UI, you have to prepare for that chaos, and the only way to do it safely is to generate mock data that mirrors these exact failure scenarios.
Instead of crossing your fingers and waiting for a production outage to see how your app crumbles, you can take control. By configuring your mock endpoints to return specific error codes on command, you can build and test your user-facing error messages and recovery logic in a completely controlled environment.
Recreating Real-World Problems
Think about it. You need to build a slick loading spinner for a slow network request and a helpful error message if the API throws a 500-level server error. Without a way to trigger these states whenever you want, you’re essentially coding blind and just hoping for the best.
This is where a tool like dotMock really shines. It gives you the power to dictate the response with precision:
- Introduce artificial delays to see how your app behaves on a sluggish connection.
- Force a 404 Not Found response to test your app's handling of missing data.
- Return a 503 Service Unavailable to make sure your retry logic actually works.
This approach flips error handling on its head, turning it from an often-neglected afterthought into a core, testable feature. You can confidently build robust loading states, intuitive error modals, and graceful fallbacks for when things inevitably go wrong. If you're interested in going deeper, we have a whole guide on how to test network latency.
Pro Tip: Don't just test for a generic "error." Simulate a variety of statuses. Your UI should handle a
401 Unauthorized(maybe by prompting a login) completely differently than a500 Internal Server Error(which might offer a retry option).
Getting good at these failure simulations is what separates a fragile application from one that delivers a dependable experience, no matter what the backend or network decides to do. You can ship features with the confidence that they won't fall apart under the pressure of real-world conditions.
Making Mock Data Part of Your Everyday Workflow

To really get the most out of dotMock, you have to move beyond treating mocking as a one-off task. The best teams I've worked with make it a core, sustainable part of their development lifecycle. It's about thinking bigger than a single endpoint and building a system that scales with your project.
A great place to start is by organizing your mock configurations logically. A battle-tested approach I always recommend is structuring your mock files by feature, not just by endpoint. This simple change keeps related data definitions together, which makes them much easier to find, understand, and update as your application evolves.
Put Your Schemas Under Version Control
Treat your API schemas and mock data definitions just like your application code—they belong in version control. Using Git to track changes to your dotMock configurations gives your entire team a single source of truth to rely on.
This one habit pays off in huge ways:
- Consistency: Everyone on the team is working from the exact same mock data definitions. No more guesswork.
- History: You get a clear, auditable trail of how an endpoint has changed over time.
- Collaboration: Developers can propose and review changes to mocks through standard pull requests.
When you treat your mock data as a first-class citizen in your repository, you pretty much eliminate the classic "well, it works on my machine" problem caused by API dependencies. It keeps everyone perfectly in sync.
This isn't just a niche practice anymore. As the need for high-quality, privacy-safe data explodes, the synthetic data market is already valued at around USD 2 billion and is projected to hit USD 10 billion by 2033.
Ultimately, a well-organized system is your ticket to generating mock data that can support a truly robust testing strategy. When your mocks are versioned, shared, and predictable, they become a powerful asset for building reliable automated tests. To see how this all comes together, check out our guide on creating a data-driven testing environment.
Common Questions on Mock Data
As you start working more with mock data, a few practical questions always seem to come up. Let's tackle some of the most common ones I hear from developers. Getting these sorted out is what turns mocking from a quick hack into a solid, everyday part of your workflow.
Can I Generate Mock Data for a GraphQL API?
You absolutely can. Even though we’ve been looking at REST examples, the same ideas apply perfectly to GraphQL. The only real difference is that you need to shape your mock JSON to match your GraphQL schema's expected response.
Your mocking tool doesn't care if it's REST or GraphQL; it's just serving a JSON file from an endpoint. This means you can easily simulate both queries and mutations, letting you build out your entire GraphQL app without waiting for the backend to be ready.
What's the Best Way to Share a Mock Server with the Team?
Hands down, the best way is to commit your mock configuration files right into your project’s repository (like Git). This creates a single source of truth for everyone on the team.
When your mock configs are version-controlled, any developer can pull the latest code and spin up the exact same mock server on their own machine. It's the ultimate way to kill the dreaded "it works on my machine" problem for API dependencies.
If you need a more permanent, shared server—maybe for the QA team or a stakeholder demo—you can deploy it to an internal dev environment or a simple cloud service. This gives them a stable URL they can hit anytime without needing to run the project locally.
How Do I Create Huge Datasets for Performance Testing?
This is a classic use case, and modern mocking tools are built for it. You can typically define how many items an array in your response should have. Need an endpoint that returns 10,000 records? Just configure it.
This is a massive help for stress-testing your frontend. You can realistically simulate how your app handles:
- List Virtualization: Does the UI crash when trying to render a massive list?
- Pagination Logic: Can your "load more" button handle tens of thousands of items gracefully?
- Client-Side Filtering: How fast can your app search or filter a huge dataset without freezing up?
Finding these performance issues early is so much cheaper and less stressful than letting them slip into production. It’s a perfect example of why you generate mock data for more than just basic functionality—you do it for rock-solid performance, too.
Ready to stop waiting and start building? With dotMock, you can create production-ready mock APIs in seconds and accelerate your entire development lifecycle. Get started for free today!